
1. 서 론
수중 전장 환경에서 운동체는 자율 주행하며 기뢰를 탐색하는 핵심적인 역할을 수행 한다. 이 때, 운동체가 운용 가능한 심도 구간 내에서 장시간 주행하며 적을 피해 은밀히 임무를 수행하는 것이 중요하기 때문에, 장애물인 해저지형을 회피하면서 명령 심도를 추종하는 기술이 필요하다[1]. 특히 해저지형 산맥 표면에 밀착 주행하여 감시정찰 임무를 수행할 때, 장애물과의 충돌 문제가 발생할 수 있으므로 해저지형과의 일정 심도 간격을 유지하며 효율적으로 주행할 필요가 있다.
일반적으로 지형 충돌 문제를 해결하기 위한 지형 추종 알고리즘은 항공기 고도 유지를 위해 활용된다[2,3]. 여기에서 기준 궤적은 항공기 전방의 지형 고도를 획득하여 생성하고, 현재 상태의 위치, 속도, 자세 정보를 이용하여 예상 비행 영역 내에서의 임무 고도를 고려한 궤적 생성 기술과 궤적 추종을 주기적으로 갱신하여 계산하는 방식이다. 이러한 항공기 지형 추종 알고리즘을 기반으로 본 논문에서는 해저지형의 심도 간격을 유지하도록 심도 명령을 추종하는 알고리즘을 제안하고, 강화학습 중에서 PPO(Proximal Policy Optimization) 알고리즘을 적용하여 최적의 행동을 찾아 명령을 효율적으로 추종하는 기법을 논의한다[4,5].
2. 해저지형 심도 추종 알고리즘 개요
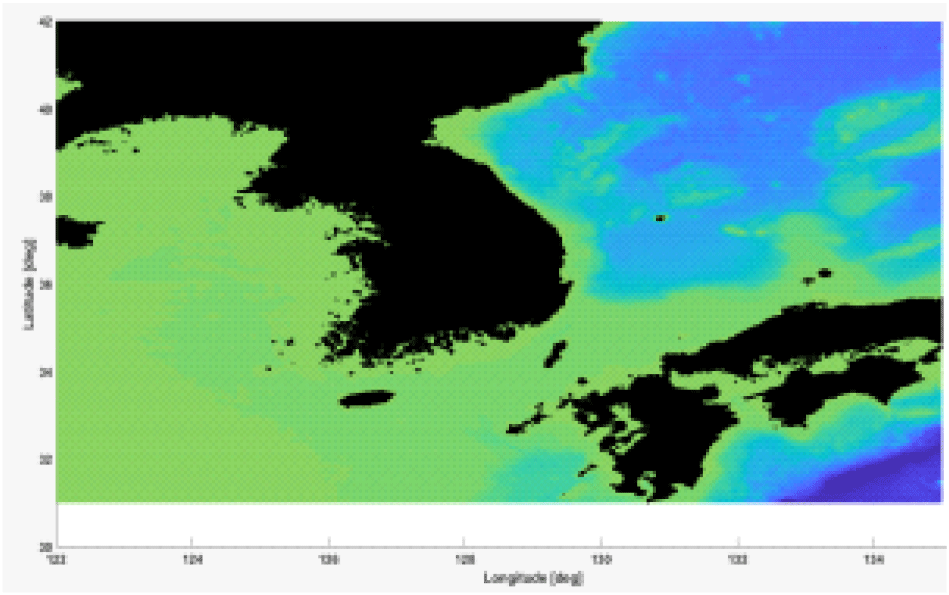
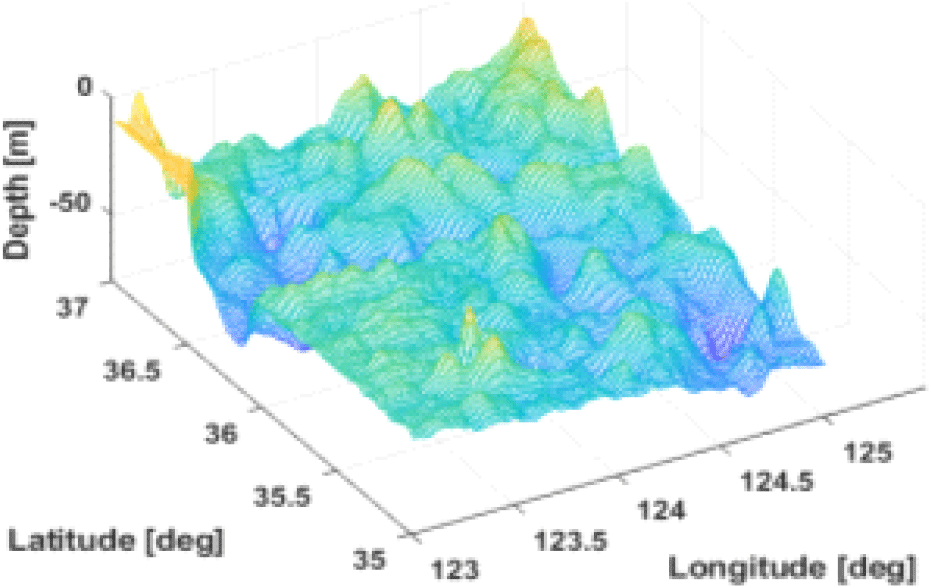
한반도 해저지형 데이터를 분석하기 위해서, 국립해양조사원에서 제공하는 위도 31~42도, 경도 122~135도 구간에 해당하는 해저지형 데이터를 Fig. 1과 같이 확보하였다. 내륙은 흑색이고, 연녹색에서 청색으로 수심이 깊어지는 것을 확인할 수 있다. Fig. 2에서는 수중 자율 운동체의 주요 주행 영역인 위도 35~37도, 경도 123~125도 구간인 서해 해역의 해저지형을 확대하여 도시한 것이다. 평균 수심은 100m 정도로 동해, 남해에 비해 얕지만 해저산의 기울기가 크며, 중첩된 해저산이 다수 분포함을 확인할 수 있다.
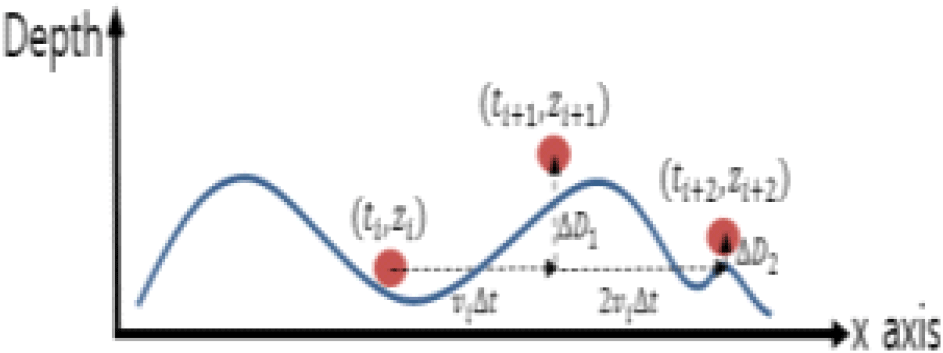
해저지형의 산맥 표면에 밀착하여 심도 명령을 추종하기 위해 필요한 알고리즘은 아래와 같이 설계 가능하다. 이 때, 필요한 수중 운동체의 파라미터로는 현재 위치, 속도, 주행 방위가 있다. 현재 해저산 위치를 기준으로 다음 시점에서의 거리에 해당하는 수심과 비교하여 심도의 상승, 유지, 하강 여부를 결정할 수 있다[6]. 하지만 해저산의 기울기가 크거나 다음 시점에서의 해저산 심도가 급변하는 구간에 대해 심도 명령이 주어지면 구동기 반응 속도가 명령을 추종하지 못하는 상황이 발생할 수 있다. 따라서, 현재 시점 ti를 기준으로 향후 시간 간격 2번에 해당하는 ti+1, ti+2일 때의 해저지형 수심 데이터를 이용하여 지형 추종 알고리즘에 반영하였다.
수중 운동체가 등속운동 할 때, 현재 시점 ti에서의 수중 운동체의 심도가 zi라고 하면 주행 속도 vi로 시간간격 Δt만큼 주행한 지점 xi+1과 2Δt만큼 주행한 지점 xi+2은 수식 1에서 산출된다. 여기에서 Δt는 사용자가 정의하는 값으로 고정된 상수이다. 수중 운동체의 주행 지점 xi+1, xi+2 각각에 대한 해저지형 수심 데이터 zi+1, zi+2의 차이를 수식 2로 계산하여 심도 명령 산출에 활용할 수 있다.
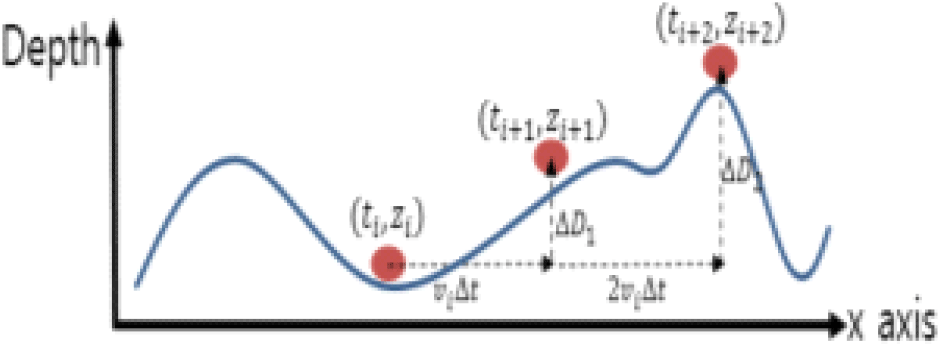
이 때, Fig. 3에 도시한 바와 같이 현재 위치를 기준으로 해저지형 수심 변화의 부호가 바뀌는 경우와 Fig. 4에 도시한 바와 같이 해저지형 수심 변화의 부호가 동일한 경우로 나누어 수식 3과 같이 심도 명령을 산출하였다.
수중 운동체가 해저지형의 산맥 표면의 경계면과 충돌하지 않고 시나리오에 따라 주어진 궤적을 잘 추종하기 위한 심도제어를 위해 종축 제어 모델을 설계하였다. 이를 위해 종축 운동에 대해 수식 4~9와 같이 선형 운동 모델을 적용하였다. 여기에서 은 수중 운동체의 형상 및 운동 특성을 반영한 선형 유체력 계수로 정의되며, 그 외에 필요한 변수는 Table 1에 정의하였다.
| 변수 | 단위 | 설명 |
|---|---|---|
| m | kg | 질량 |
| W | N | 중력=mg |
| B | N | 부력 |
| Vtot | m/s | 주행 속력 |
| Iyy | kgm2 | y축에 대한 관성량 |
| bx,bz | m | 부력중심과 무게중심 간의 x, z 축 거리 차이 |
| θ 0 | rad | 정상상태 받음각 |
운동 방정식으로부터 산출하는 운동 변수 Xlong은 Table 2에 정의한 바와 같다.
| 변수 | 단위 | 설명 |
|---|---|---|
| w | m/s | 동체좌표계 기준 수직면 속력 |
| q | rad/s | 수직면 각속도 |
| θ | rad | 수직면 자세 |
| z | m | 심도 |
운동 모델에서 심도 명령 추종을 위한 수직타각 δe 제어를 PD 제어기 형태로 설계하였고, 수식 10과 같다.
여기에서 δe는 수직타각 입력, zcmd는 목표 심도값, z는 현재 심도값, θcmd는 목표 피치각도, θ는 현재 피치각도를 의미한다. 이 때, θcmd는 자세 안정화를 위해 0으로 설정하였고, 종축 운동으로부터 심도 변화가 만들어지기 때문에 θ가 심도명령 입력에 대해 빠르게 반응하게 설계하였다. Fig. 5와 같이 MATLAB Simulink를 이용하여 게인 Kp,Kd를 설정하였다.
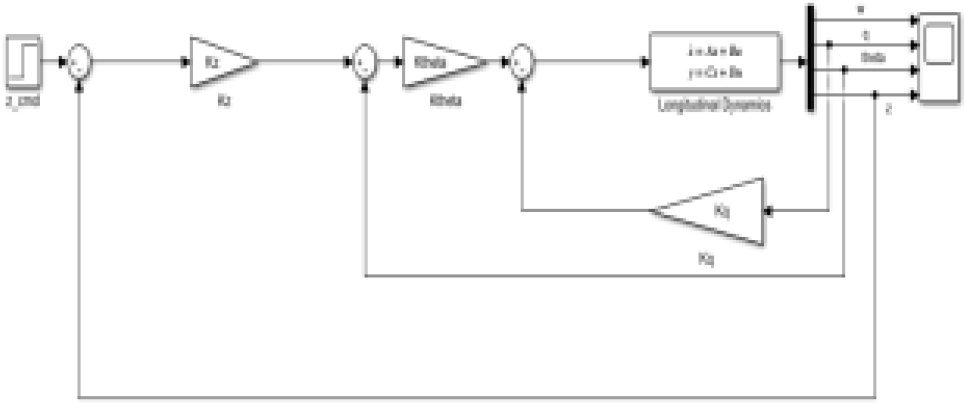
3. 강화학습 적용 방안
PPO 알고리즘은 정책 기반의 강화학습 기법을 의미한다. 정책 업데이트 시 급격한 변화를 방지하기 위해 클리핑 기법을 도입한 것이 특징으로 수식 11과 같이 손실 함수(LCLIP (θ))를 정의할 수 있다. 여기에서 rt (θ)는 수식 12와 같이 이전 정책(πold)과 새로운 정책(πθ) 간의 확률 비를 의미하고, At는 어드벤티지 함수로 현재 상태에서 해당 행동이 얼마나 유리한지 나타낸다. ϵ은 클리핑 계수로 급격한 변화를 방지하는 역할을 하고, 본 논문에서는 0.1을 적용하였다. 손실함수에서 입력값은 여러 시간 간격 t에 대한 어드벤티지 값, 클리핑 기법을 적용한 어드벤티지 값이고 출력값은 최솟값 평균(Et)이다.
이러한 과정을 반복함으로써 안정성과 성능을 동시에 보장하는 대표적인 정책 최적화 방법이다. 이를 심도 추종을 위한 보상 함수 설계에 활용하기 위해서 수식 13을 적용한다. 여기서 목표 심도는 dtarget(t)이고, 현재 심도는 d(t)이다. ut는 제어 입력, Ccollision은 충돌 여부이며, α,β,γ는 각각 심도 오차, 제어명령, 충돌여부에 대한 가중치 계수이다.
수식 11의 손실함수가 0에 가까워지도록 학습하여 산출되는 제어 입력 값이 수식 10에서 산출된 타각 명령에 반영되도록 수식 14와 같이 피드백 된다.
4. 해저지형 회피 및 심도 추종 성능 분석 결과
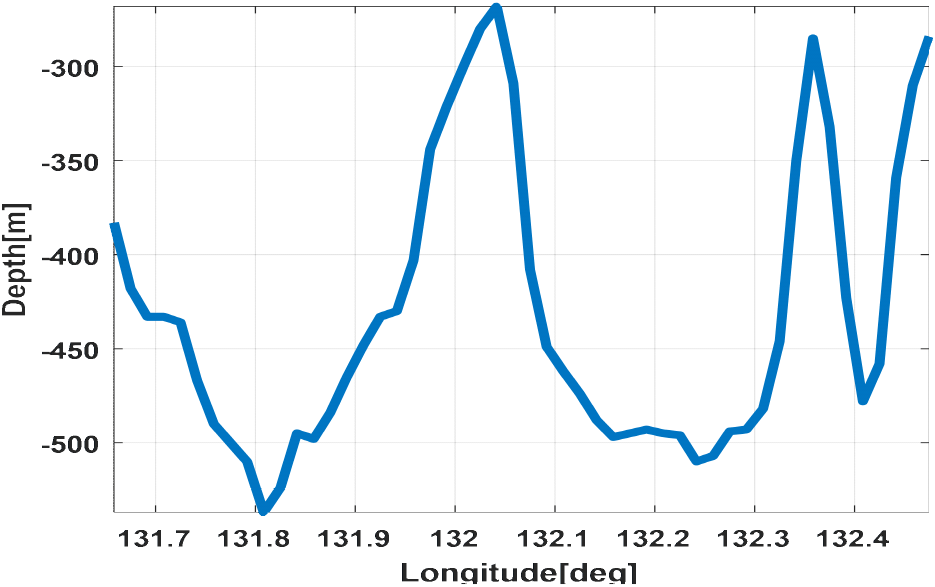
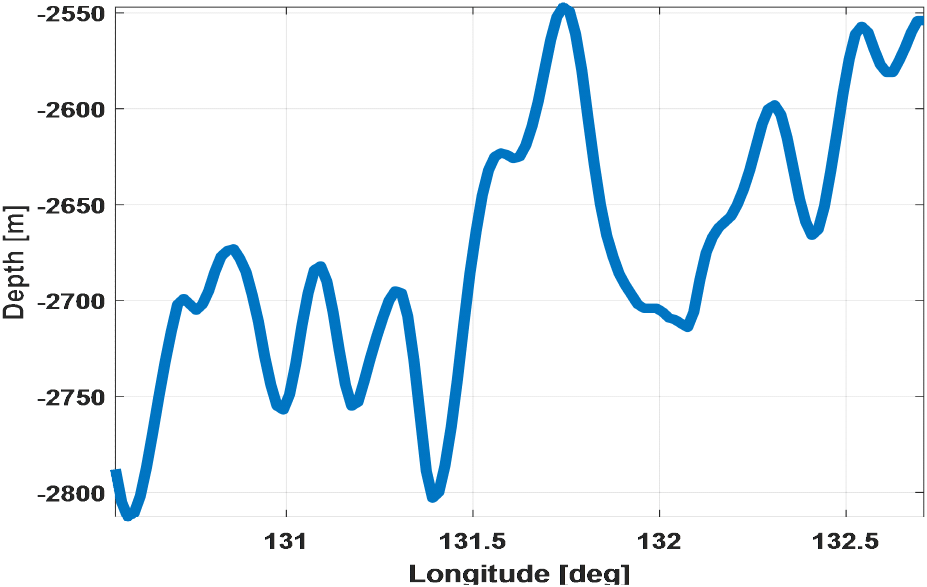
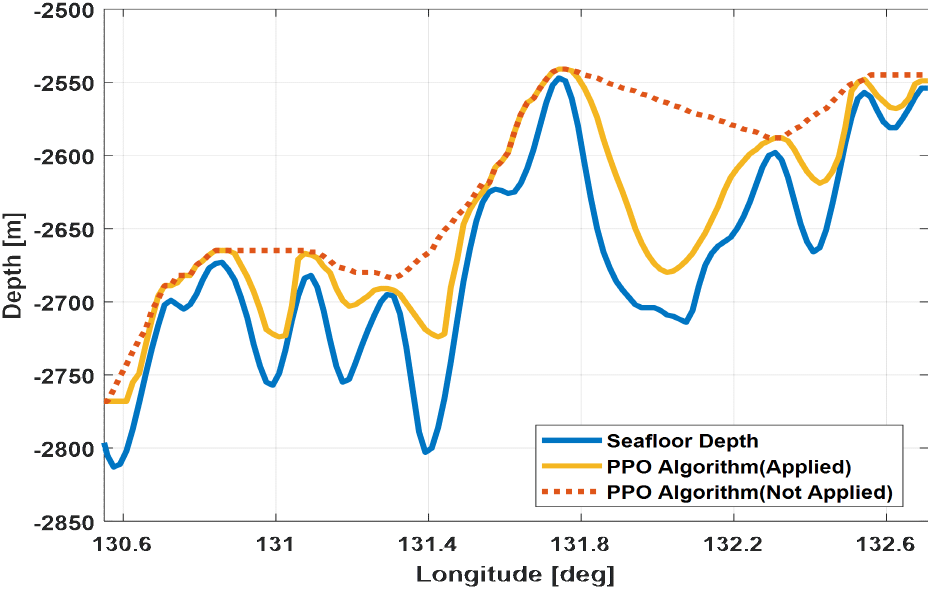
3장에서 기술한 수중 자율 운동체의 종축 선형 운동 모델과 PPO 알고리즘을 활용한 종축 제어 모델 설계에 대한 성능 분석을 위해 주행 시나리오를 Fig. 6과 Fig. 7에 도시한 바와 같이 수립하였다. 위도는 한 각도로 고정인 상태로 경도 방향으로 운동체가 직진 주행하는 것으로써, Fig. 6 시나리오1은 위도 35.3도, 경도 131.5~132.5도 구간, Fig. 7 시나리오2는 위도 36.2도, 경도 130.5~132.7도 구간을 주행하도록 하였다. 그림에 표시된 청색 선은 해당 구간에 대한 해저지형 심도를 도시한 것이다. 시나리오 입력 변수는 Table 3에 기술하였다.
| 변수 | 값 | 단위 | 설명 |
|---|---|---|---|
| [x,y,z] | [002780] | m | NED 좌표계 기준 위치 |
| V | 2 | m/s | 속력 |
| Δt | 1 | sec | 모의시간 간격 |
| [φθψ] | [000] | rad | 자세 |
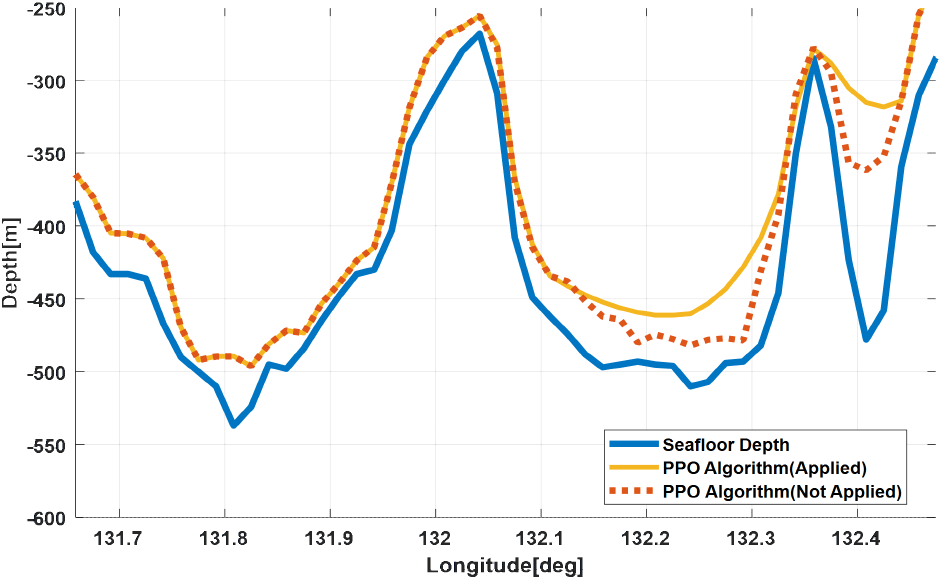
두 가지 시나리오에 대해 수중 운동체의 심도 추종 성능을 분석한 결과는 Fig. 8, Fig. 9에 도시한 바와 같다. 해저지형 심도에 대해 충돌 가능성이 있기 때문에 수중 자율 운동체의 직경을 고려하여 30m 이상 고도 차이를 두고 주행하도록 설정하였고, 해저지형의 기울기를 반영하여 효율적인 제어가 이루어지도록 하였다. Fig. 8의 주행경로에 대해 경도 131.9 ~ 132.05도 부근에서 심도가 300m 이상 변화하는 구간에 대해서는 다음 지점인 132.1도 부근의 심도 데이터에 맞추어 주행하는 특징을 보였다. 이는 배터리 효율을 극대화하여 장시간 주행하기 위한 것이다. PPO 기반의 강화학습을 적용했을 때 보다 부드럽게 심도 변화가 이루어짐을 확인하였다. Table 4는 시나리오 1에 대해 강화학습 적용 여부에 따른 해저지형 심도와 심도 추종 결과 성능을 분석한 것이다. 강화학습을 적용했을 때, 심도 변화에 빠르게 대응하기 때문에 오차 평균이 크지만, 배터리 효율에서 우수함을 보였다.
| 해저지형과의 오차 | 강화학습 미적용 | 강화학습 적용 |
|---|---|---|
| 평균[m] | 3.17 | 11.39 |
| 분산[m] | 2.53 | 1.82 |
| 배터리 효율 | 강화학습 미적용 | 강화학습 적용 |
| 잔여[%] | 20.1 | 35.7 |
Fig. 9에서 131.4 ~ 131.7도 부근에서의 심도 변화에 대해서도 효율적으로 심도 명령을 추종함을 확인하였다. Table 5는 시나리오 2에 대해 강화학습 적용 여부에 따른 해저지형 심도와 심도 추종 결과 성능을 분석한 것이다. 강화학습을 적용했을 때, 심도의 기울기 차이를 부드럽게 추종하기 때문에 오차 평균이 작으면서도 배터리 효율에서 큰 차이 없음을 보였다.
| 해저지형과의 오차 | 강화학습 미적용 | 강화학습 적용 |
|---|---|---|
| 평균[m] | 20.62 | 3.74 |
| 분산[m] | 4.21 | 1.56 |
| 배터리 효율 | 강화학습 미적용 | 강화학습 적용 |
| 잔여[%] | 34.6 | 32.1 |
5. 국방 적용성 및 향후 개선 방향
본 연구 결과는 수중 자율 운동체의 제어기 설계에 있어 강화학습의 활용을 통해 정확하고 효율적인 설계안을 제공한다. 주행 경로 상에 존재하는 해저지형을 사전에 파악하여 배터리 소모는 낮추는 방향으로 심도 명령을 실시간으로 계산함으로써 회피 경로를 수립하는 것에 있어 효과적임을 알 수 있다. 예를 들어 Fig. 6이나 Fig. 7의 특정 구간에서 수중 자율 운동체의 속력을 고려하여 초 당 0.9m 정도의 해저지형 심도 변화가 발생하였을 때, 명령 심도를 0.9m/s의 기울기를 가지고 실시간 산출하는 것이 아닌 2초 후의 해저지형 심도 값을 이용하여 현재 심도와의 차이를 이용하여 심도 명령을 우선 산출하였다. 그 후, PPO 알고리즘을 활용한 강화학습을 기반으로 최적화던 심도 명령을 산출하도록 학습하여 배터리 소모율을 최소화하도록 하였다.
현재 수중 운동체의 자율 주행에 있어 예측 가능한 방해 요소인 해저지형에 대한 연구가 활발히 진행되어 왔다. 특히 한반도 주변 해역은 불규칙성과 수심의 변화가 존재하기 때문에 사전에 해저지형 데이터를 이용하여 경로 수립에 활용할 필요가 있다. 이를 위해 본 논문에서는 국립해양연구원에서 제공하는 해저지형 수심 데이터를 이용하여 운동체의 주행 시나리오에 해당하는 해저지형 영역을 산출하였다. 해저지형의 심도를 모의 시간 간격에 따라 확인하여 해저지형 산맥 경계에 밀착하여 심도를 추종하도록 강화학습을 적용하였지만, 강화학습의 경우 사용자가 손실함수를 설정하는 방식이나 PPO 알고리즘에서의 클리핑 계수 설정 값에 따른 학습시간이나 정확도에 차이가 발생하는 한계가 있다.
따라서 이를 개선하기 위해 우선적으로 서해 해역의 해저지형 외에도 동해, 남해 해역의 다양한 해저지형 영역에 대한 학습이 필요하다. 강화학습의 경우 학습 데이터 양이 많을수록 학습 정확도 증가 및 연산 시간 감소의 결과를 가져오기 때문에 사전에 위도 31~42도, 경도 122~135도 구간의 데이터에 대해 학습할 필요가 있다.
두 번째로는 PPO 알고리즘에서의 클리핑 계수 설정 값 변경에 따른 학습 효과 분석이 필요하다. 현재 설정한 값은 학습에 사용하는 대푯값을 적용한 것인데, 0.2까지 변경하며 손실함수 값이 어떻게 변하는지 확인하여야 하고, 심도 명령 산출 시 유연하게 해저지형 산맥을 추종하는지 비교할 필요가 있다.
끝으로, PPO 알고리즘 외에 장애물 회피에서 부드러운 동작이 가능하도록 TD3(Twin Delayed Deep Deterministic Policy Gradient) 알고리즘을 적용하여 심도 명령이 튀는 현상을 개선할 수 있다. 특히 TD3 알고리즘은 엔트로피 보상을 사용하여 탐색 성능이 우수함으로써 다양한 해저지형에서의 적절한 정책 학습이 가능할 것이다.
6. 결 론
수중 전장 환경에서 자율 운동체가 주행할 때, 해저산과 같은 특정 장애물을 회피하여 심도를 추종하는 것이 중요하다. 이 때, 시간당 배터리 소모량을 최소로 하여 효율적으로 주행하는 것이 핵심이다. 특히 해저지형 산맥 표면에 밀착 주행하는 것은 적으로부터 피탐 효과를 극대화하며, 장애물 충돌을 최소화 할 수 있기 때문에 일정 심도 간격을 유지하며 효율적으로 주행할 필요가 있다.
이에 따라 본 논문에서는 항공기 고도 유지를 위해 활용되는 지형 추종 알고리즘을 기반으로 해저지형의 심도 간격을 유지하며 추종하는 알고리즘을 제안하였고, PPO 알고리즘 기반의 강화학습을 통해 최적의 심도 명령을 산출하는 기법을 제안하였다. 이 때, 해저지형 데이터는 대한국립해양연구원에서 제공하는 한반도 해역 데이터를 이용하였고, 주요 분석 구역인 서해안 해역을 기준으로 경도 변화에 따른 해저지형의 심도를 추출하여 적용하여 분석하였다.
지형 추종을 위한 심도 명령을 생성하고 수중 자율 운동체의 선형 운동 모델로부터 PD제어기를 모델링하여 종축에 대한 안정성 및 조종성을 확보하였다. 제어기에 입력되는 심도 명령에 대해 PPO 알고리즘 기반의 강화학습을 수행하여 배터리 소모율을 최소화하면서, 부드럽게 심도 변화를 추종할 수 있도록 설계하였다. 이를 검증하기 위해 2가지의 주행 시나리오에 대한 분석을 수행하였고, 효율적인 심도 명령 산출 및 추종을 확인하였다.
하지만 추후에 다양한 해저지형에 대한 강화학습 수행을 통해 심도 명령 산출의 정확도 및 연산속도 최적화를 이뤄내야 하고, 수중 운동체의 횡축 운동에 대한 제어기 설계 또한 보강하여 3차원의 해저지형 상에서 지형을 추종하는지 분석할 필요가 있다. 예를 들어 해저지형에서 특징점으로 불리는 해저산의 기울기나 중첩도에 따라 최적화된 심도 명령 산출 값이 변경될 수 있기 때문에 종축 뿐만 아니라 횡축에 대한 학습 또한 필요하다.
이러한 운동체의 제어기 설계를 위한 다양한 강화학습 알고리즘 적용 및 분석을 통해 수중 자율 운동체의 해저지형 회피 및 추종 성능을 확인함으로써, 명령 심도 추종을 위한 제어기 성능을 주행 전에 사전 분석하고, 주행시간과 배터리 효율을 최대화하는 경로 계획 수립에 활용할 수 있을 것으로 기대된다.